GPT#2 - Programmieren mit ChatGPT
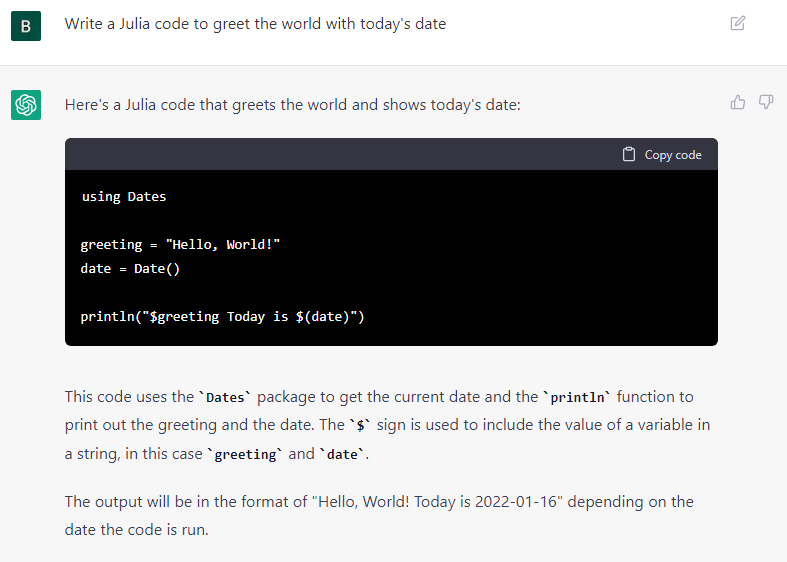
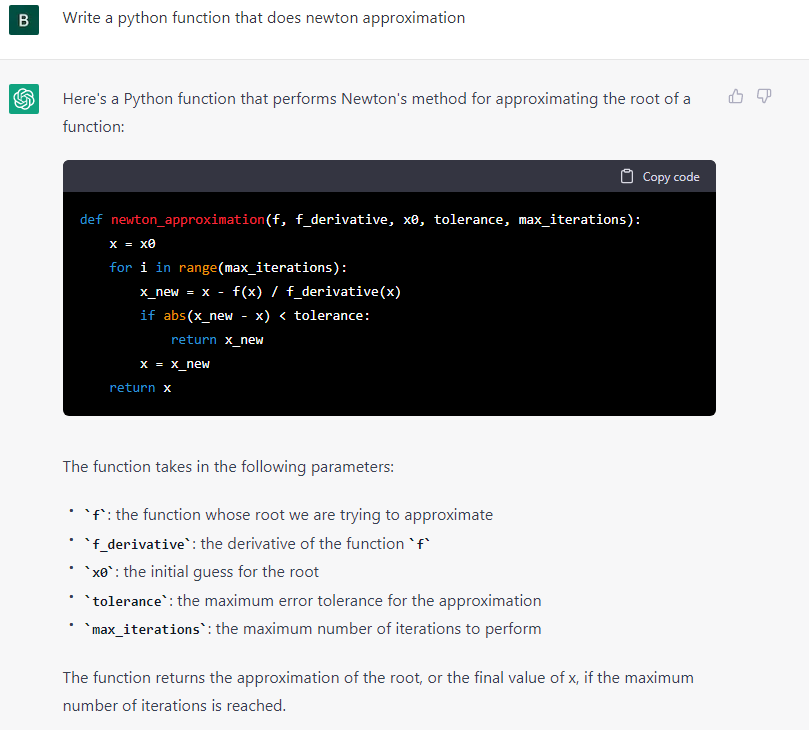
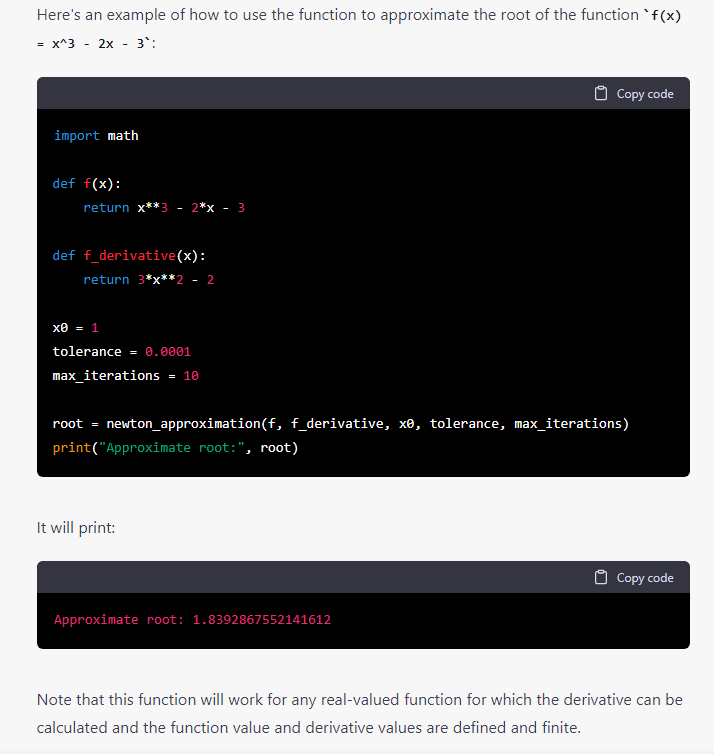
Aufgabe: Einfache und algorithmisch anspruchsvollere Code-Generierung in verschiedenen Programmiersprachen. Hello World mit Datum in Julia, eine Funktion für das Newton-Verfahren in Python. Weitere Experimente, u.a. KI Verfahren in weiteren Beispielen, hier nicht aufgeführt.
Kommentar: ChatGPT generiert die kleineren und größeren Code Snippets hier korrekt (anders als z.B. in #12) und fügt Erläuterungen zu Aufbau und Nutzung mit Beispiel hinzu.
Es wirkt zunächst verblüffend, dass das Sprachmodell sinnvollen Code zu konkreten Aufgaben generieren kann. Andererseits sind die Beispiele Standardfälle, die in Tutorials und Blogs im Internet als Code zu finden sind. (Versuche Google: Python function for Newton Iteration). Dennoch, die Aufbereitung und Darstellung der Antworten zeigt hohe Sprach- und Erklärungskompetenz (um menschliche Begriffe zu verwenden) des Generators. Es wäre zu prüfen, wie die Ergebnisse von Wiederholungen der Prompts aussehen.
Die Frage nach „originärer“ Programmierung wird in #11 noch einmal aufgegriffen, bei dem Versuch einen Prompt zu erstellen für eine Programmieraufgabe, die so evtl. im Internet noch nicht existiert.
Übersetzung der Erläuterungen ins Deutsche mit DeepL.com empfohlen.
Task & Prompt: Bernhard Thomas (B)
Generator: ChatGPT (OpenAI Symbol)
Translator: n/a
Editing: n/a (ChatGPT Originaltext)
Authoring: Bernhard Thomas
15.01.2023
bernhard.thomas@interscience.de
Naive Bayes Modell löst das Even-Odd Learning Problem
KI im Informatikunterricht
Dieser Beitrag kann als Grundlage für die Einführung des Themas „Künstliche Intelligenz“ im Schulunterricht eingesetzt werden. Er illustriert „Maschinelles Lernen“ anhand einer für die Schüler* einfach verständlichen Aufgabe mittels einer Data Analytics Methode: Naive-Bayes. Die Aufgabe kann mit „Papier und Bleistift“ durchgeführt werden. Die Voraussetzungen beschränken sich auf Erstellen von Tabellen, Auszählen von Häufigkeiten und Berechnung von relativen Häufigkeiten.
Die Blogserie „Six not so easy pieces for AI” (Sechs nicht so einfache Aufgaben für AI) begann in 2019 mit der einfachen Fragestellung, ob AI in der Lage ist, eine der einfachsten „intellektuellen“ Leistungen zu erbringen, nämlich zu lernen, ob eine Zahl gerade oder ungerade ist. (Siehe hier.)
Abstrakte Fragestellung - Allgemeines Schema
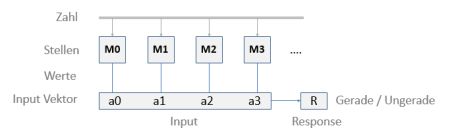
Hier bedeuten die einzelnen Attribute des Input-Vektors die Dezimalstellen einer ganzen Zahl, beginnend bei den „Einern“ ganz rechts. Der Wertebereich (Kategorien-Labels) ist jeweils 0,1,…,9. Die Response im Supervised Learning gibt jeweils an, ob die Zahl gerade oder ungerade ist. Die entsprechenden Klassen sind 0 (für Gerade) und 1 (für Ungerade). Im trainierten Zustand gibt R die „Vorhersage“ für eine Testzahl.
Es ist wichtig zu bedenken, dass ein "lernendes KI-System" hier kein Konzept von Zahlen, Dezimalstellen und deren Bedeutung innerhalb einer Zahl (z.B. Einer, Zehner etc.) hat. Die Inputs sind für das System nichts weiter als eine Liste von Ziffern.
Das Training-Szenario
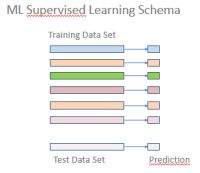
Als Training-Daten wird eine Anzahl von ganzen positiven Zahlen in Form einer Liste der einzelnen Dezimalstellen samt der richtigen Klassifikation in gerade / ungerade vorgegeben.
Als Testdaten werden einzelne Zahlen oder ein Set von Zahlen in dieser Form ohne Klassifikation verwendet. Diese sind nicht in den „Lernvorgang“ eingegangen. Das Ergebnis (Prediction) kann mit dem wahren Wert verglichen werden.
Die ML Methode
Als ML-Methode verwenden wir hier, anders als in der erwähnten Blog-Serie, ein Naive-Bayes Verfahren. Kurz erläutert, wertet das NB-Verfahren die Trainingsdaten aus und bestimmt – mittels der Bayes-Formel - die bedingte Wahrscheinlichkeit dafür, dass, gegeben eine m-stellige Zahl (Input-Vektor), das Ergebnis R=0 ("gerade") ist. Entsprechend für R=1 ("ungerade"):
P(R=0|a0 a1 … am)
Der Input-Vektor ist einfach die Ziffernfolge der Zahl, wobei für die Dezimalstellen untereinander keine Abhängigkeit besteht. (Grundannahme für die Gültigkeit von „Naive“ Bayes.)
Im „gelernten“ Zustand kann das Modell (auch Classifier genannt) für unbekannte Zahlen b = b0 b1 … bm entscheiden, ob diese gerade oder ungerade ist, anhand der berechneten Wahrscheinlichkeiten P(R=0|b) und P(R=1|b) – je nachdem, welche der Wahrscheinlichkeiten größer ist.
(In der Regel reichen wenige Zahlen für das Training aus, sofern man die sog. Glättung im Classifier „ausschaltet“. Die Glättung kompensiert Fälle, in denen eventuell einzelne Werte in den Input-Daten nicht vorkommen (missing data), und sich damit Schwierigkeiten in der Auswertung ergeben können.)
Für unser gerade-ungerade-Lernen Problem zeigt sich, dass die o.a. Wahrscheinlichkeiten P entweder 0.0 oder 1.0 sind. Im Sinne der Blogserie haben wir es hier also mit „starkem Lernen“ zu tun.
Ist das Lernverfahren auch „robust“? In der Blogserie hatten wir damit ein Lernverfahren gekennzeichnet, das ein gewisses Maß an Fehlern in den Trainingsdaten vertragen kann und trotzdem „richtig“ lernt. Und dabei auch die Fehler „richtigstellt“ (im Code-Beispiel: 5% Zufallsstörung)
Da die Input-Werte ganzzahlig (Kategorien) sind (0,..9) und die Response-Klassen ebenfalls (0,1), setzen wir hier die Variante CategoricalNB() aus der scikit-learn Toolbox an.
Outline des Algorithmus „Gerade/Ungerade Lernen“
Als Programm liegt dieses Beispiel als ein Jupyter Notebook vor, ablauffähig und mit kleinen Zwischentexte zur Erläuterung. Wegen Problemen bei der Kompatibilität der Dokumentenformate liegt das Notebook als html-Datei hier: NB_even-odd_problem_notebook
Der übliche, grobe Ablauf ist wie folgt:
- Problem Defintion: Beschreibung der Aufgabe als Text
- Problem-Dimensionen und Datensatzumfang (Code-Zelle)
- Parameter für Problem-Varianten (optional, Code)
- Generierung des Datensets: (Code-Zellen) Inputzahlen per Zufallsgenerator, dargestellt als Liste von Dezimalziffern je Zeile, davon N Zeilen (Matrix-Struktur Nx6). Zugehörige Klassifikation (R-Werte) als Liste von 0 und 1 für jede Matrix-Zeile (Zahl). Beispiel:
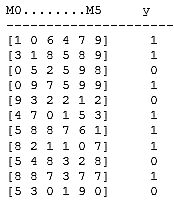
- Datenset-Aufteilung Tranings-/Testdaten: z.B. 70% zu 30% (Code)
- Categorical Naive Bayes Modell: Modell-Defintion und Training (g_u_model.fit()) mit den Trainingsdaten (Code)
- Ergebnisse: 7.1Test-Beispiele, 7.2 Genauigkeit der Klassifikation durch das Modell für Trainings- und Testdaten, 7.3 „Innere“ Daten des trainierten Modells (s. Code-Zellen)
- (Optional) Aufgaben-Varianten: 8.1 Verfälschen der Klassifikationen in den Trainingsdaten zur einem kleinen Prozentsatz per Zufall. 8.2 Probieren, Teilbarkeit durch 5 zu lernen. (Code Zellen)
- (Optional) Experimentieren: Teilbarkeit durch 3, 4 o.ä. Warum funktioniert Naiv-Bayes hier nicht?
Links zu NaiveBayes Methoden
https://scikit-learn.org/stable/modules/naive_bayes.html
https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.CategoricalNB.html
https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/
Q-IBM - Wie man Zugang zum IBM Quanten-Computing bekommt
Die Qubit-Algorithmen dieser Blog-Serie zu verstehen und nachzuvollziehen macht mehr Spaß, wenn wir sie selber erstellen und laufen lassen können. Das geht mit IBM Quantum Experience, einer frei zugänglichen Umgebung, in der man Qubit-Circuits entwerfen und testen kann. Testen auf einem Simulator oder sogar echten IBM Quanten-Computern.
Wie kommt man da dran?
Zugang zur IBM Quantum-Computing-Umgebung
Es findet wie heute üblich, alles im Browser statt (Web-Application). Gesonderte Apps für Smartphone und Tablet gibt es für IBM Q Experience Apps (noch) nicht. Und über den Browser geht es dort nicht so richtig gut. Es wird also ein "richtiges" Gerät - PC, Laptop, Mac oder ähnliches - empfohlen.
Im Browser gibt man ein
https://quantum-computing.ibm.com/login
Man sieht ... alles auf Englisch, natürlich! Daher ein paar Hinweise.
Beim ersten Mal muss man sich zunächst registrieren. (Später wird man direkt auf seine aktuelle Arbeitsumgebung geführt (s. Dashboard, unten)). Zum Registrieren dient der Link hinter "Create an IBM Account". Damit startet man die Registrierung. Ist erkennbar, dass der Link von einem deutschsprachigen PC aufgerufen wurde, findet der weitere Dialog auf Deutsch statt: "Bei IBM anmelden". "Sie haben noch kein Konto?" - Genau! Deshalb geht es dort weiter: Link "IBMId erstellen" (Die IBMId wird dann bei weiteren Login's gebraucht.)
Nun wird es wieder Englisch: "Sign up for an IBMId" ist die Seite, auf der E-mail, Name und Passwort und Land (Germany) eingegeben werden. Mit "Next" geht's weiter zu "Verify email", d.h. zur Überprüfung, ob die E-mail Adresse gültig ist und im rechtmäßigen Besitz des Users. Es wird dazu ein 7-stelliger Code an die eingetragene E-mail Adresse geschickt. Also, in der Mailbox nachsehen und die 7 Zeichen in die kleine Box "Verification token" eintragen. Anschließend endlich "Create account" (Konto erstellen) anklicken. Dann erscheint - unvermeidbar - erst noch die Einwilligung zum IBM Konto Datenschutz. Mit "Proceed" bestätigen, und dann ist es schon geschafft.
Danach kann man die Kontoinformationen (E-Mail Adresse, Password) zum Login verwenden: Link-Adresse wie oben und dann auf "Bei IBM anmelden" die E-mail-Adresse eingeben und "Weiter". Wenn gewünscht, kann man vorher das Kästchen "Merken" ankreuzen. Dann noch das Passwort unter "Kennwort" eingeben. Und schon ist man drin!
Halt - nein! Beim ersten Mal muss man noch das IBM Quantum End User Agreement ankreuzen und "Accept & continue" klicken. Das ist halt so üblich, dass man die "Geschäftsbedingungen" akzeptiert. Und wie bei (kosten-)freien Diensten üblich, wird man anschließend gebeten, etwas über sich preis zu geben. "Your institution" ist ein Muss (Sternchen-Feld): hier gibt man z.B. die Schule an oder irgendwas. Der Rest ist optional: Drop-down Auswahl über seine Vorkenntnisse mit "quantum", Freitext-Feld um anzugeben, was man mit IBM Q Experience machen will, und Auswahl-Liste, welche Informationen man zu IBM Q Experience erhalten will (per E-mail).
Dann endlich "Continue" und jetzt ist man (fast) drin. Wo drin?
Erscheinungsbild (User Interface) der IBM Quantum-Computing-Umgebung
Anfangs oder immer wieder beim Login wird man mit einem Fenster konfrontiert, das uns ein "Get started" Tutorial anbietet. Nicht schlecht, das mal durchzugehen, wenn man Zeit hat oder schon ein wenig mit dem Circuit Composer "gespielt" hat. Mit "Close" lehnen wir das Angebot ab.
Wenn man seine Zugangsdaten gespeichert hat und den gleichen Browser benutzt, wird man schon direkt auf seine aktuelle Arbeitsumgebung geführt (s. Dashboard, unten).
Anm.: Es ist natürlich alles auf Englisch, von daher erfordern die Tutorials und weitere Dokumente möglicherweise Englischkenntnisse, die über das schulische Niveau einer Mittelstufe hinausgehen.
Das User Interface öffnet sich mit einer Welcome-Seite. Neben der Begrüßung findet man dort einige Informationen über das, was man schon gemacht hat: Welche Circuits, welche Ergebnisse (results) anstehen (pending), welche zuletzt angefallen sind (Latest).
Spannend ist die Liste rechts der gerade verfügbaren "Backends". Das sind die Quanten-Computer, die weltweit zur Verfügung stehen (online). Zu jedem Eintrag gibt es Informationen darüber, wo er steht, wieviel Qubits er hat - und wieviel "Jobs" (Programmausführungen) in der Warteschlange stehen. Am Ende der Liste ist der "virtuelle" Quanten-Computer aufgeführt, der ibmq_qasm_simulator, den man aktuell mit bis zu 32 Qubits nutzen kann.
Diese Informationen sind umrahmt von einer Menüleiste mit teilweise kryptischen Symbolen. Die Menüleiste befindet sich links (s. Bild unten).
Einige Menü-Punkte des User Interfaces
Oben in der Ecke deuten drei waagerechte Striche an, dass man hiermit das Menü ausklappen kann, so dass man sehen kann, was die Symbole bedeuten. Hier einige kurz erläutert:
- Dashboard: So heißt die Welcome Seite
- Tools | Circuit Composer: Enthält im Kern den grafischen Circuit Composer mit den möglichen Gates und den (einstellbaren) Qubit / Mess-Bit Linien. Seit August 2020 sind hier noch eine ganze Reihe weiterer Widgets (Fensterchen) mit dargestellt.
- Das für Messergebnisse (Measurement Probabilities) ist für die Blog-Serie interessant.
- Statevector (Zustandsvektor) zeigt die (theoretischen) Faktoren an (als farbige Säulen), mit denen die verschiedenen Basiszustände in einer Superposition vertreten sind, so wie sie vom Qubit-Algorithmus gerade erzeugt wird. In der Blog-Serie auch als Koordinaten bezeichnet. Im Fachjargon des Quanten-Computing spricht man auch von der Amplitude.
- Rechts gibt es noch einen Bereich für Dokumente und Tutorial-Empfehlungen. Alternativ (Tabs direkt darüber) kann man sich hier den QASM Skript-Code zur Grafik anzeigen lassen und verändern, oder die aktuelle Job-Übersicht.
- Das ist leider ziemlich viel auf einmal und wird gegenüber der Vorversion leicht unübersichtlich für unsere Zwecke. Aber man gewöhnt sich daran und kann über den Menüpunkt View einiges "abwählen".
- Die einzelnen Menüpunkte oben in der Leiste mit ihren Unter-Optionen muss man Zug um Zug kennenlernen. Zuviel, um das alles hier zu erklären. Es wird sicher auch deutschsprachige Tutorials dazu geben.
- Tools | Quantum Lab: Der Bereich, in dem man Qubit-Algorithmen in Form von Python-Notebooks und mit Verwendung der Qubit-Programmbibliothek Qisqit erstellen und managen kann. Wir hatten ein Beispiel dafür im Kommentar zu Blog Q8.
- Tools | Results: Zeigt die Übersicht der Resultate von QC-Jobs an.
- Resources | Docs und Support: IBM Q Experience Dokumentationen, Tutorials und Zugang zu Q&A und anderen Support-Formen.
Der Circuit Composer in Kurzfassung
Ein kurzer Blick auf den Circuit Composer. Er erscheint innerhalb des User-Interfaces mit seiner Menüleiste am linken Rand, wie oben erklärt.
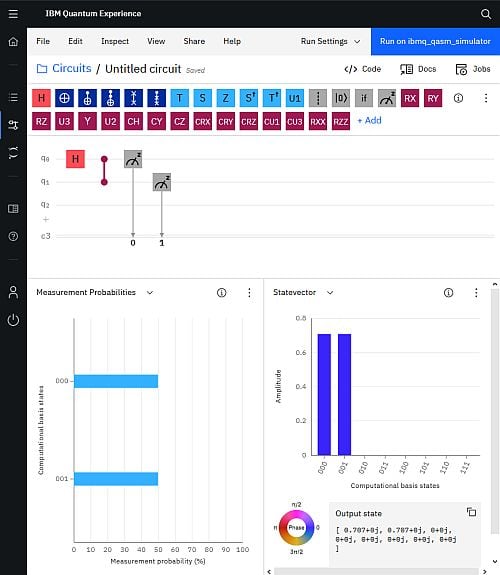
- Der Circuit Composer hat eine eigene Menüleiste, waagerecht oben im Widget.
- Im oberen Bereich (Widget) hat man die "Partitur". Die Gates und die Qubit- und Messbit-Linien. Natürlich kann man diese einstellen über Edit.
- Darunter hat man weitere Widgets, z.B. die Measurement Probabilities, also die theoretische Vorhersage der Messergbnisse. Oder den "Zustandsvektor", der den (Superpositions-) Zustand des Qubit-Systems zeigt. Gezeigt wird der Zustand, der am Ende des Circuits resultieren würde. Alle nicht benötigten Widgets kann man "verstecken", z.B. über View.
- Über Run Settings und Run on ... kann man den Qubit Circuit starten.
- Die Ergebnisse findet man unter Jobs, einer von 3 Inhalten, die man in einem Widget ganz rechts darstellen kann. (Im Bild ausgeblendet.) Die anderen beiden enthalten Dokumentationen und Hinweise (Docs) und das QASM Code-Skript zum aktuellen Circuit.
- Zwischen oberer Menüleiste und den Gates-Symbolen findet man eine typische Pfadangabe: Verzeichnis/Datei. Hier Circuits/Untitled Circuit. D.h. für den gezeigten Circuit haben wir noch keinen Namen vergeben. Das kann man mit dem Stift-Symbol ändern. Der Stift erscheint, wenn sich der Mauszeiger über den Circuit Namen befindet. Das Verzeichnis Circuits ist das Standard-Verzeichnis, in dem man alle seine gespeicherten Circuits (saved) wiederfindet.
- Die Details und Unterpunkte findet man am besten heraus, indem man sie ausprobiert. Allerdings muss man sich mit einigen englischen Begriffen vertraut machen - was aber nicht so schwierig sein sollte, da die meisten ohnehin auch schon im deutschen Sprachgebrauch verwendet werden.
Wenn diese Zusatzinformation aus dem Kontext von Q8 heraus aufgerufen wurde: hier gehts zurück zu Q8.